
Bodies, Minds, and the Artificial Intelligence Industrial Complex, Part two
Picture a relatively simple human-machine interaction: I walk two steps, flick a switch on the wall, and a light comes on.
Now picture a more complex interaction. I say, “Alexa, turn on the light” – and, if I’ve trained my voice to match the classifications in the electronic monitoring device and its associated global network, a light comes on.
“In this fleeting moment of interaction,” write Kate Crawford and Vladan Joler, “a vast matrix of capacities is invoked: interlaced chains of resource extraction, human labor and algorithmic processing across networks of mining, logistics, distribution, prediction and optimization.”
“The scale of resources required,” they add, “is many magnitudes greater than the energy and labor it would take a human to … flick a switch.”1
Crawford and Joler wrote these words in 2018, at a time when “intelligent assistants” were recent and rudimentary products of AI. The industry has grown by leaps and bounds since then – and the money invested is matched by the computing resources now devoted to processing and “learning” from data.
In 2021, a much-discussed paper found that
“the amount of compute used to train the largest deep learning models (for NLP [natural language processing] and other applications) has increased 300,000x in 6 years, increasing at a far higher pace than Moore’s Law.”2
An analysis in 2023 backed up this conclusion. Computing calculations are often measured in Floating Point OPerations. A Comment piece in the journal Nature Machine Intelligence illustrated the steep rise in the number of FLOPs used in training recent AI models.
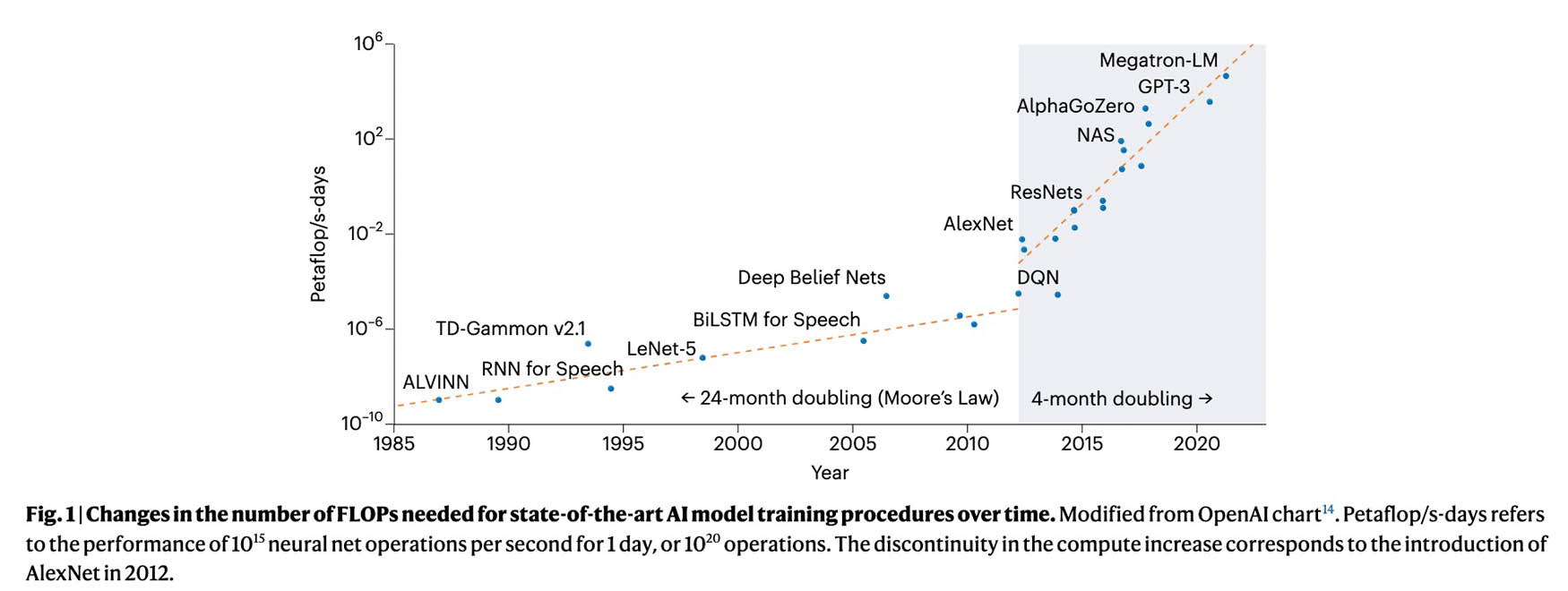
Changes in the number of FLOPs needed for state-of-the-art AI model training, graph from “Reporting electricity consumption is essential for sustainable AI”, Charlotte Debus, Marie Piraud, Achim Streit, Fabian Theis & Markus Götz, Nature Machine Intelligence, 10 November 2023. AlexNet is a neural network model used to great effect with the image classification database ImageNet, which we will discuss in a later post. GPT-3 is a Large Language Model developed by OpenAI, for which Chat-GPT is the free consumer interface.
With the performance of individual AI-specialized computer chips now measured in TeraFLOPs, and thousands of these chips harnessed together in an AI server farm, the electricity consumption of AI is vast.
As many researchers have noted, accurate electricity consumption figures are difficult to find, making it almost impossible to calculate the worldwide energy needs of the AI Industrial Complex.
However, Josh Saul and Dina Bass reported last year that
“Artificial intelligence made up 10 to 15% of [Google’s] total electricity consumption, which was 18.3 terawatt hours in 2021. That would mean that Google’s AI burns around 2.3 terawatt hours annually, about as much electricity each year as all the homes in a city the size of Atlanta.”3
However, researcher Alex de Vries reported if an AI system similar to ChatGPT were used for each Google search, electricity usage would spike to 29.2 TWh just for the search engine.4
In Scientific American, Lauren Leffer cited projections that Nvidia, manufacturer of the most sophisticated chips for AI servers, will ship “1.5 million AI server units per year by 2027.”
“These 1.5 million servers, running at full capacity,” she added, “would consume at least 85.4 terawatt-hours of electricity annually—more than what many small countries use in a year, according to the new assessment.”5
OpenAI CEO Sam Altman expects AI’s appetite for energy will continue to grow rapidly. At the Davos confab in January 2024 he told the audience, “We still don’t appreciate the energy needs of this technology.” As quoted by The Verge, he added, “There’s no way to get there without a breakthrough. We need [nuclear] fusion or we need like radically cheaper solar plus storage or something at massive scale.” Altman has invested $375 million in fusion start-up Helion Energy, which hopes to succeed soon with a technology that has stubbornly remained 50 years in the future for the past 50 years.
In the near term, at least, electricity consumption will act as a brake on widespread use of AI in standard web searches, and will restrict use of the most sophisticated AI models to paying customers. That’s because the cost of AI use can be measured not only in watts, but in dollars and cents.
Shortly after the launch of Chat-GPT, Sam Altman was quoted as saying that Chat-GPT cost “probably single-digit cents per chat.” Pocket change – until you multiply it by perhaps 10 million users each day. Citing figures from SemiAnalysis, the Washington Post reported that by February 2023, “ChatGPT was costing OpenAI some $700,000 per day in computing costs alone.” Will Oremus concluded,
“Multiply those computing costs by the 100 million people per day who use Microsoft’s Bing search engine or the more than 1 billion who reportedly use Google, and one can begin to see why the tech giants are reluctant to make the best AI models available to the public.”6
In any case, Alex de Vries says, “NVIDIA does not have the production capacity to promptly deliver 512,821 A100 HGX servers” which would be required to pair every Google search with a state-of-the-art AI model. And even if Nvidia could ramp up that production tomorrow, purchasing the computing hardware would cost Google about $100 billion USD.

Detail from: Nvidia GeForce RTX 2080, (TU104 | Turing), (Polysilicon | 5x | External Light), photograph by Fritzchens Fritz, at Wikimedia Commons, licensed under Creative Commons CC0 1.0 Universal Public Domain Dedication
A 457,000-item supply chain
Why is AI computing hardware so difficult to produce and so expensive? To understand this it’s helpful to take a greatly simplified look at a few aspects of computer chip production.
That production begins with silicon, one of the most common elements on earth and a basic constituent of sand. The silicon must be refined to 99.9999999% purity before being sliced into wafers.
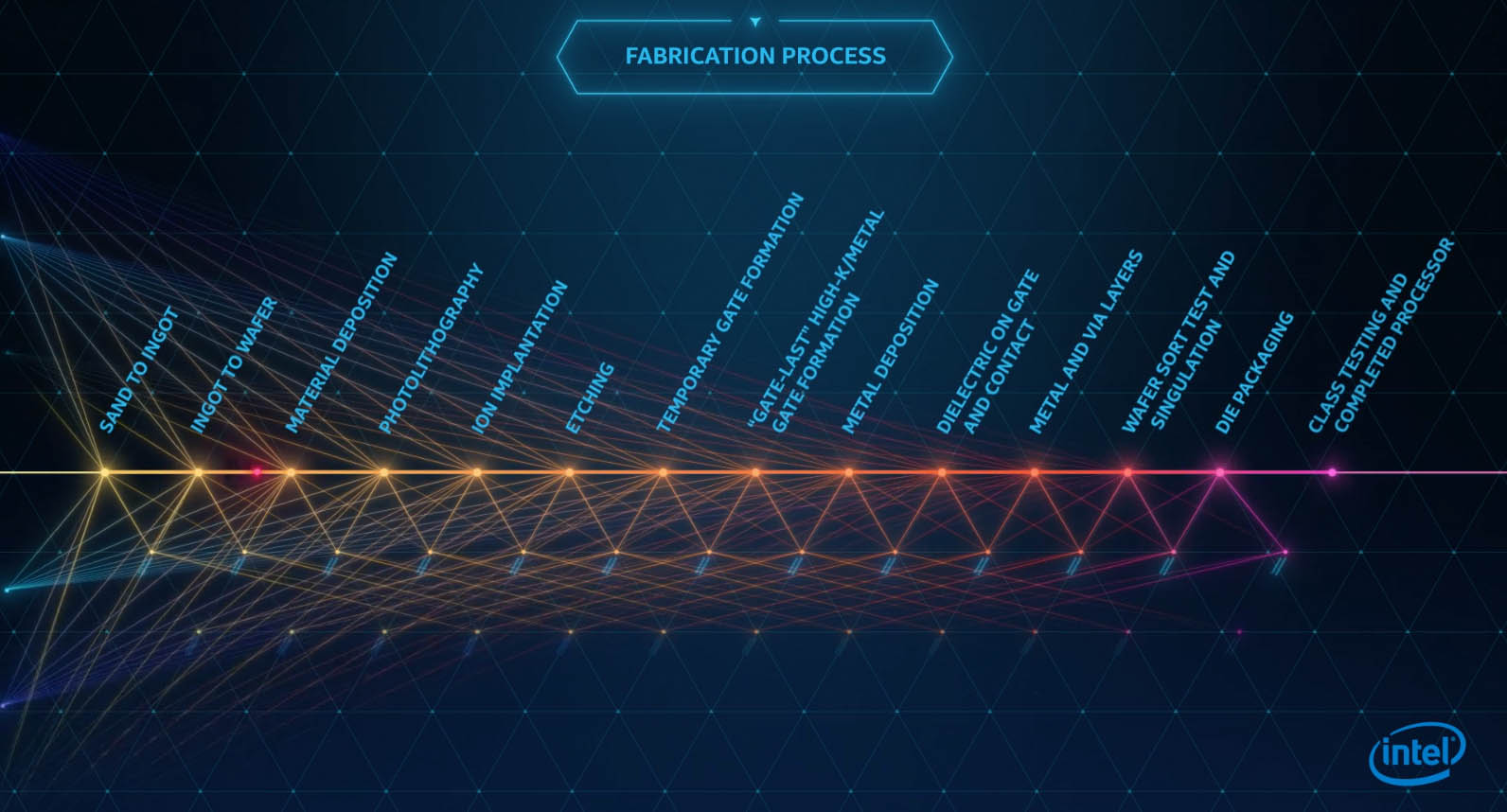
Image from Intel video From Sand to Silicon: The Making of a Microchip.
Eventually each silicon wafer will be augmented with an extraordinarily fine pattern of transistors. Let’s look at the complications involved in just one step, the photolithography that etches a microscopic pattern in the silicon.
As Chris Miller explains in Chip War, the precision of photolithography is determined by, among other factors, the wavelength of the light being used: “The smaller the wavelength, the smaller the features that could be carved onto chips.”7 By the early 1990s, chipmakers had learned to pack more than 1 million transistors onto one of the chips used in consumer-level desktop computers. To enable the constantly climbing transistor count, photolithography tool-makers were using deep ultraviolet light, with wavelengths of about 200 nanometers (compared to visible light with wavelengths of about 400 to 750 nanometers; a nanometer is one-billionth of a meter). It was clear to some industry figures, however, that the wavelength of deep ultraviolet light would soon be too long for continued increases in the precision of etching and for continued increases in transistor count.
Thus began the long, difficult, and immensely expensive development of Extreme UltraViolet (EUV) photolithography, using light with a wavelength of about 13.5 nanometers.
Let’s look at one small part of the complex EUV photolithography process: producing and focusing the light. In Miller’s words,
“[A]ll the key EUV components had to be specially created. … Producing enough EUV light requires pulverizing a small ball of tin with a laser. … [E]ngineers realized the best approach was to shoot a tiny ball of tin measuring thirty-millionths of a meter wide moving through a vacuum at a speed of around two hundred miles an hour. The tin is then struck twice with a laser, the first pulse to warm it up, the second to blast it into a plasma with a temperature around half a million degrees, many times hotter than the surface of the sun. This process of blasting tin is then repeated fifty thousand times per second to produce EUV light in the quantities necessary to fabricate chips.”8
Heating the tin droplets to that temperature, “required a carbon dioxide-based laser more powerful than any that previously existed.”9 Laser manufacturer Trumpf worked for 10 years to develop a laser powerful enough and reliable enough – and the resulting tool had “exactly 457,329 component parts.”10
Once the extremely short wavelength light could be reliably produced, it needed to be directed with great precision – and for that purpose German lens company Zeiss “created mirrors that were the smoothest objects ever made.”11
Nearly 20 years after development of EUV lithography began, this technique is standard for the production of sophisticated computer chips which now contain tens of billions of transistors each. But as of 2023, only Dutch company ASML had mastered the production of EUV photolithography machines for chip production. At more than $100 million each, Miller says “ASML’s EUV lithography tool is the most expensive mass-produced machine tool in history.”12

Landscape Destruction: Rio Tinto Kennecott Copper Mine from the top of Butterfield Canyon. Photographed in 665 nanometer infrared using an infrared converted Canon 20D and rendered in channel inverted false color infrared, photo by arbyreed, part of the album Kennecott Bingham Canyon Copper Mine, on flickr, licensed via CC BY-NC-SA 2.0 DEED.
No, data is not the “new oil”
US semi-conductor firms began moving parts of production to Asia in the 1960s. Today much of semi-conductor manufacturing and most of computer and phone assembly is done in Asia – sometimes using technology more advanced than anything in use within the US.
The example of EUV lithography indicates how complex and energy-intensive chipmaking has become. At countless steps from mining to refining to manufacturing, chipmaking relies on an industrial infrastructure that is still heavily reliant on fossil fuels.
Consider the logistics alone. A wide variety of metals, minerals, and rare earth elements, located at sites around the world, must be extracted, refined, and processed. These materials must then be transformed into the hundreds of thousands of parts that go into computers, phones, and routers, or which go into the machines that make the computer parts.
Co-ordinating all of this production, and getting all the pieces to where they need to be for each transformation, would be difficult if not impossible if it weren’t for container ships and airlines. And though it might be possible someday to run most of those processes on renewable electricity, for now those operations have a big carbon footprint.
It has become popular to proclaim that “data is the new oil”13, or “semi-conductors are the new oil”14. This is nonsense, of course. While both data and semi-conductors are worth a lot of money and a lot of GDP growth in our current economic context, neither one produces energy – they depend on available and affordable energy to be useful.
A world temporarily rich in surplus energy can produce semi-conductors to extract economic value from data. But warehouses of semi-conductors and petabytes of data will not enable us to produce surplus energy.
Artificial Intelligence powered by semi-conductors and data could, perhaps, help us to use the surplus energy much more efficiently and rationally. But that would require a radical change in the economic religion that guides our whole economic system, including the corporations at the top of the Artificial Intelligence Industrial Complex.
Meanwhile the AI Industrial Complex continues to soak up huge amounts of money and energy.
Open AI CEO Sam Altman has been in fund-raising mode recently, seeking to finance a network of new semi-conductor fabrication plants. As reported in Fortune, “Constructing a single state-of-the-art fabrication plant can require tens of billions of dollars, and creating a network of such facilities would take years. The talks with [Abu Dhabi company] G42 alone had focused on raising $8 billion to $10 billion ….”
This round of funding would be in addition to the $10 billion Microsoft has already invested in Open AI. Why would Altman want to get into the hardware production side of the Artificial Intelligence Industrial Complex, in addition to Open AI’s leading role in software operations? According to Fortune,
“Since OpenAI released ChatGPT more than a year ago, interest in artificial intelligence applications has skyrocketed among companies and consumers. That in turn has spurred massive demand for the computing power and processors needed to build and run those AI programs. Altman has said repeatedly that there already aren’t enough chips for his company’s needs.”15
Becoming data
We face the prospect, then, of continuing rapid growth in the Artificial Intelligence Industrial Complex, accompanied by continuing rapid growth in the extraction of materials and energy – and data.
How will major AI corporations obtain and process all the data that will keep these semi-conductors busy pumping out heat?
Consider the light I turned on at the beginning of this post. If I simply flick the switch on the wall and the light goes off, the interaction will not be transformed into data. But if I speak to an Echo, asking Alexa to turn off the light, many data points are created and integrated into Amazon’s database: the time of the interaction, the IP address and physical location where this takes place, whether I speak English or some other language, whether my spoken words are unclear and the device asks me to repeat, whether the response taken appears to meet my approval, or whether I instead ask for the response to be changed. I would be, in Kate Crawford’s and Vladan Joler’s words, “simultaneously a consumer, a resource, a worker, and a product.”15
By buying into the Amazon Echo world,
“the user has purchased a consumer device for which they receive a set of convenient affordances. But they are also a resource, as their voice commands are collected, analyzed and retained for the purposes of building an ever-larger corpus of human voices and instructions. And they provide labor, as they continually perform the valuable service of contributing feedback mechanisms regarding the accuracy, usefulness, and overall quality of Alexa’s replies. They are, in essence, helping to train the neural networks within Amazon’s infrastructural stack.”16
How will AI corporations monetize that data so they can cover their hardware and energy costs, and still return a profit on their investors’ money? We’ll turn to that question in coming installments.
Notes
1 Kate Crawford and Vladan Joler, Anatomy of an AI System: The Amazon Echo as an anatomical map of human labor, data and planetary resources”, 2018.
2 Emily M. Bender, Timnit Gebru and Angelina McMillan-Major, Shmargaret Shmitchell, “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” ACM Digital Library, March 1, 2021. Thanks to Paris Marx for introducing me to the work of Emily M. Bender on the excellent podcast Tech Won’t Save Us.
3 “Artificial Intelligence Is Booming—So Is Its Carbon Footprint”, Bloomberg, 9 March 2023.
4 Alex de Vries, “The growing energy footprint of artificial intelligence,” Joule, 18 October 2023.
5 Lauren Leffer, “The AI Boom Could Use a Shocking Amount of Electricity,” Scientific American, 13 October 2023.
6 Will Oremus, “AI chatbots lose money every time you use them. That is a problem.” Washington Post, 5 June 2023.
7 Chris Miller, Chip War: The Fight for the World’s Most Critical Technology, Simon & Schuster, October 2022; page 183
8 Chip War, page 226.
9 Chip War, page 227.
10 Chip War, page 228.
11 Chip War, page 228.
12 Chip War, page 230.
13 For example, in “Data Is The New Oil — And That’s A Good Thing,” Forbes, 15 Nov 2019.
14 As in, “Semi-conductors may be to the twenty-first century what oil was to the twentieth,” Lawrence Summer, former US Secretary of the Treasury, in blurb to Chip War.
15 “OpenAI CEO Sam Altman is fundraising for a network of AI chips factories because he sees a shortage now and well into the future,” Fortune, 20 January 2024.
16 Kate Crawford and Vladan Joler, Anatomy of an AI System: The Amazon Echo as an anatomical map of human labor, data and planetary resources”, 2018.




